DynamoDB 的 NoSQL 設計
之前多次提到NoSQL與RDBMS設計的不同,這次就來講講DynamoDB資料表設計實務的建議。
一般關聯式資料庫入門書籍,都會在前三章或者一開始就解釋資料庫正規化的概念,其目的在建立標準化的資料模型,在資料一致性與約束性更好,也能很有彈性的查詢資料。但是反過來說在資料查詢上就相對昂貴,經常性的需要在多個資料表間進行索引串聯,往往一次查詢都需要多個索引預分析以配合。
相反的NoSQL的DynamoDB設計最開始需要的工作不是資料結構,而是優先釐清每個需求使用案例,預先評估分析資料存取案例的熱點,才來開始規劃NoSQL資料表設計。
在 DynamoDB 中製作關聯式資料模型的第一步。
當然最好是AWS文件中的DynamoDB 最佳實務都能大致瀏覽一次,會比較清楚設計細節,不過以下將提及幾種常用資料形式。
其實就是大型檔案資料,直白的講就是應該把大型資料純放在S3,DynamoDB僅維護項目ID。
事件、交易紀錄明細表,只存在新增資料,以及熱點也在新資料的查詢。你或許應該將資料按照時間過期建立與區分不同的資料表(這點RDBMS也有相同的設計方式)。
更進一步的,如果你的時間資料更常是依項目進行存取,也可以以項目作為PK,時間作為Range Key。
還有特殊屬性存留時間(TTL),可以為你的Item設定過期時間,逾期DynamoDB將自動進行刪除,而且這個刪除動作不收取花費。
你應該考量的是存儲時間序列資料表的項目內容,應該要包含所有查詢資料所需的屬性,而不需要再另外查找其他資料表關聯。
在 DynamoDB 中打造關聯式資料模型的範例
文件中較詳細的舉例Primary Key與GSI(全域次要索引)再命名上將不使用實體屬性名稱的多載設計方式,此種方式能最大化的將不同項目儲存在一個資料表中,並且有效的利用20 個全域次要索引的預設限制。
不過我想更清楚的示範其差異,如果原有關聯式項目描述可能如下圖所示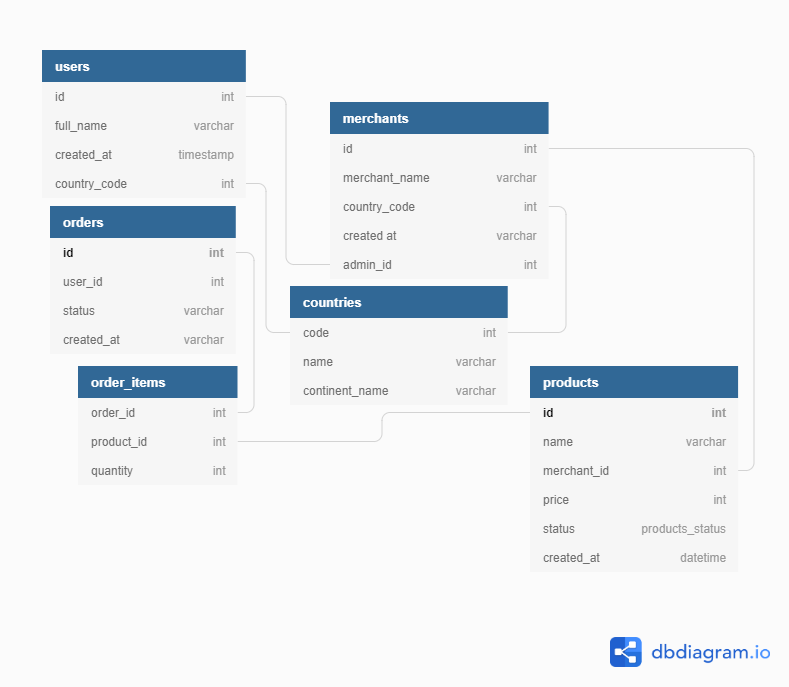
在NoSQL設計下的一種方案可以是這樣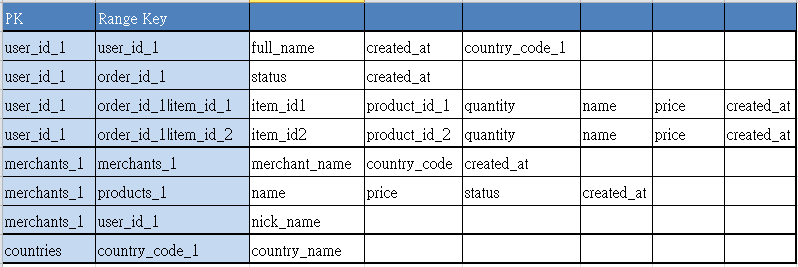
這樣設計的目的如下
總和來說還是以實際存取案例調整設計,但是目前為止的案例示範都是給予一些設計使用技巧為主,如
項目多對多的設計模式較為特殊,AWS建議了相鄰清單設計模式。可以參考以下上面文件連結當中的圖例示範,簡單講就是如果AB互相關聯,那麼所有組合關聯都會有一份item。
以Primary Key當中Partition Key(前者) & Sort Key(後者)來看的話

